Facebook Like Predictor
A Facebook status likes predictor for EECS 349 at Northwestern University.
Navigation: Motivation Solution Testing and Training Key Results Authors-
Source code:
- View on Github Paper:
- Download PDF

Facebook is one of the core ways people express themselves and share their lives. College students often post about their life events such as getting an internship or graduating, but on a day to day basis students often struggle to decide whether their thoughts are worth sharing. Will my friends "like" this status? Will they think it is annoying? Will they laugh? College students' social lives are measured by the judgement of others, and one simple scale is the number of likes that a status receives. Craving approval from their friends, a student may want to predict how popular a particular post would be in order to decide if it was worth sharing. Instead of impatiently waiting for the first few "likes" to appear on their status, the student could rest assured that their status would be popular among their friends.
Solution
We aimed to predict the number of likes a status would garner by creating a model with data pulled through Facebook’s Graph API and Facebook Query Language (FQL). We generated temporary tokens through Facebook’s Graph Explorer to grab the statuses of all of our friends to do our testing. The attributes we considered were:
- User's number of friends
- User's age
- User's gender
- Time status was posted (month and time of day)
- Time since last status
- Average number of likes a user gets
- Message score (a score assigned based on the words used in the status)
To build our model, we tried both linear regression and nearest neighbor learning algorithms to test various combination of attributes.
Testing and Training
We pulled a total of 49,216 statuses from around 700 users. This set was then divided into a 5,000 status set for later testing, and two 22,108 status sets; one half for training our dictionary to generate message score and the other half to train the learner. We measured success for various combinations of attributes and learning algorithms by the correlation indicated by Weka and the root mean squared error (RMSE). Naturally, we aimed for high correlations and low RMSEs.
Key Results
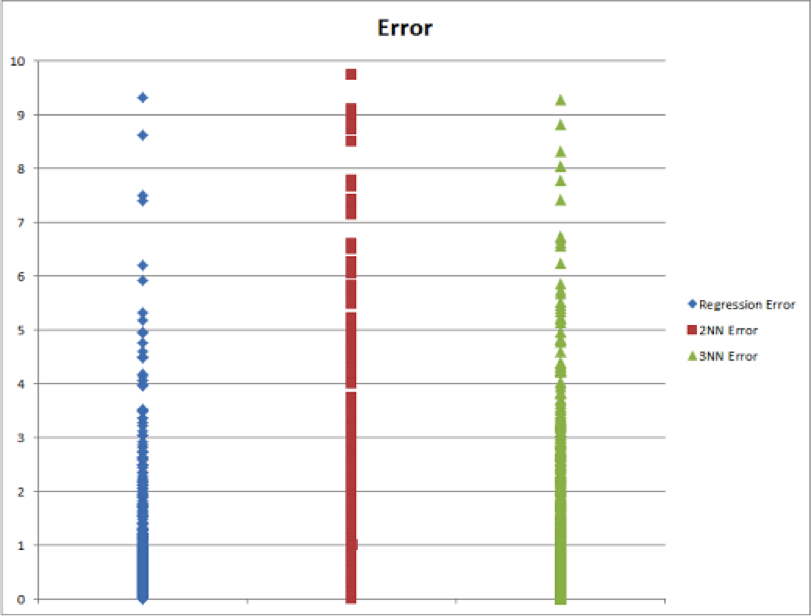 Fig 1. Error for linear regression, 2NN and 3NN classifiers
Fig 1. Error for linear regression, 2NN and 3NN classifiers
We found that linear regression performed the best both in terms of RMSE and correlation. It also has the lowest actual error when results were taken out of the logarithmic form. Though massively better than our baseline measurement (ZeroR), all of our algorithms did not predict consistently accurate results on the test set. The most important attribute seems to be the message score, followed by the average number of likes a user gets.
Authors
The authors and contributors for this project were Kevin Chen, Basil Huang, and Brittany Lee of Northwestern University for EECS 349: Machine Learning with Professor Doug Downey. They can be contacted regarding this project at {kevinchen2016, basilhuang2014, brittanylee2015} @ u dot northwestern dot edu or by using the button in the navigation bar.
For more detailed information on this project, please read the paper.